


 0
0
Jak wspomniałem w poprzednim wpisie na temat wysokiej dostępności technik uzyskania wysokiej dostępności systemu z wykorzystaniem Microsoft SQL Server jest kilka. Poznaliście już Database Mirroring, dzisiaj kilka słów o SQL Cluster.
Rozwiązanie tzw. klastrów nie jest niczym nowym i stosowane jest w wielu obszarach IT, możemy wyróżnić klaster SQL czyli są to dwie lub więcej działające instancje SQL Server, które w przypadku awarii natychmiast przełączają swoje działanie tak aby aplikacja była cały czas dostępna.
Dodatkowo rozwiązania klastrów występują chociażby w urządzeniach sieciowych, można budować klastry urządzeń, które zapewniają ich redundancje, występują również całe klastry komputerowe, które w założeniu mają działać jak jeden komputer.
Ale wracając do tematu SQL Cluster to rozwiązanie pozwala nam utrzymać infrastrukturę na wysokim poziomie dostępności dla całej instancji. Tak jak wspomniałem dla Database Mirroring wymagane jest konfigurowanie tego mechanizmu dla każdej bazy, w której chcemy uzyskać HA, w przypadku klastra konfiguracja obejmuje całą instancję, więc wszystkie bazy danych na niej znajdujące się są od razu ujęte w tej konfiguracji.
Poniższy schemat prezentuje bardziej zaawansowaną konfigurację klastra z wykorzystaniem tzw. AlwaysOn Failover Cluster czyli grupy instancji umieszczonej w ramach klastra.
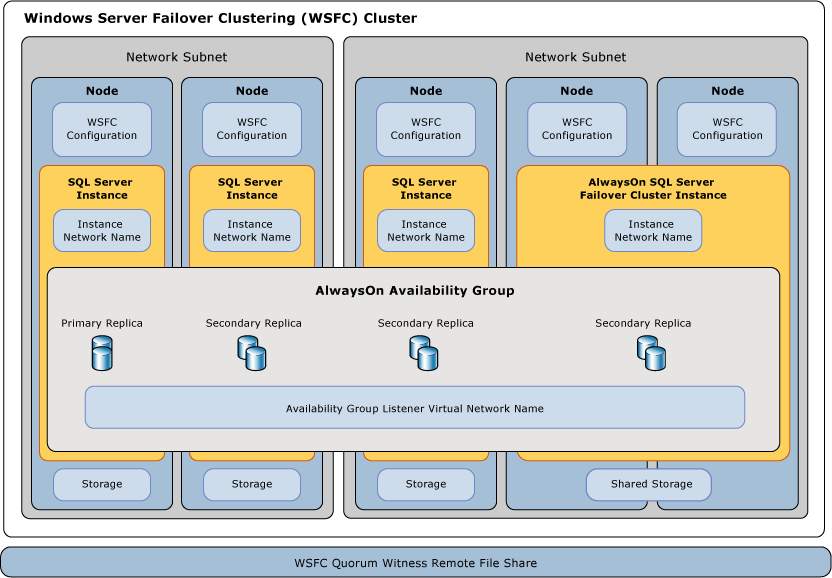
Instancje współdzielą określony zasób sieciowy, na którym składowana jest baza danych i każdy tzw. węzeł (z ang. node) klastra ma dostęp do tej bazy i w przypadku awarii pozostałych węzłów, może z niego skorzystać.